Another look at Non-Naiveté in the Internet's Hidden Science Factory
Sarah Marshall was the focus of a recent PBS article and was described as a “…sort of cyber guinea pig, providing a steady stream of data to academic research”; having worked on MTurk for the past five years, she estimates having completed approximately 20,000 academic surveys. Reddit's reaction to this article suggests this figure may be quite low by the standards of other workers.
A central argument of the PBS article is that many MTurk workers are no longer naïve to common social scientific methods, that such experience has altered workers' behavior in ways that may make them unsuitable for certain research, and — at least judging from the article's focus — this problem may largely be due to those, like Sarah, who have been working consistently on MTurk for years, often referred to as “super-turkers.” 1 Perhaps, if non-naiveté is the product a long work history, MTurk's high turnover rate (at least as of 2010) provides a naïve group of workers at lower HIT levels. 2 Can researchers just restrict their studies to those having completed under 5,000 to 10,000 or so HITs and assume safety?
To test this, I included three questions along with a survey sent to over 600 workers which assessed respondents' number of completed HITs, as well as (1) previous exposure to an exchange task and (2) previous exposure to a fake partner. 3
1) Exposure to exchange tasks
Exchange tasks are ubiquitous in the social sciences. They involve two or more partners giving, receiving, or negotiating the exchange of tokens and form the basis of much of our research on trust, cohesion, power, prosocial behavior and, more broadly, rational choice. The PBS article mentioned that many workers are so overexposed to such tasks that they no longer respond as normal humans. I encountered hints of this altered behavior from a worker who admitted that, regardless of a study's content, she or he always splits tokens 50/50 with exchange partners. This behavior has simply become a reflex.
To what extent have workers been exposed to exchange tasks?
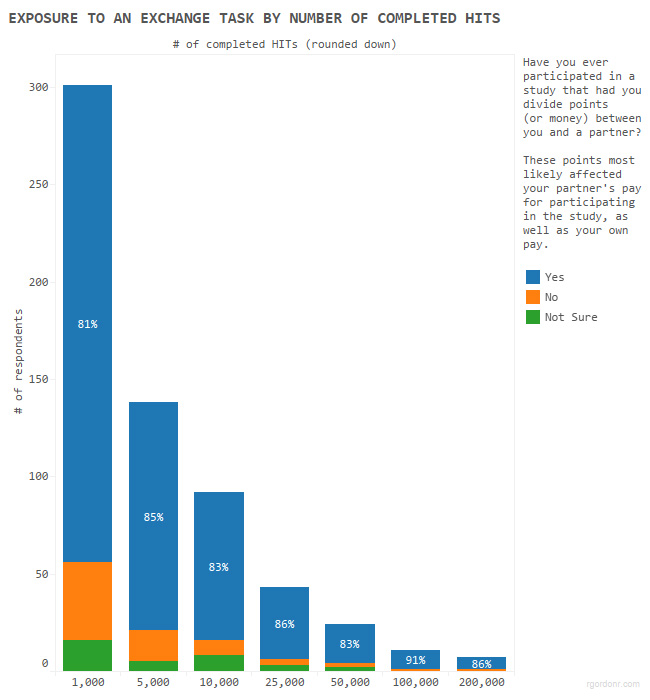
Although I did not measure “overexposure” (i.e. how often a worker encounters such tasks), we can at least infer that the problem of inital exposure is extensive and not limited to super-turkers.
2) Exposure to fake partners
An element common to experimental research involves telling participants they are interacting with real partners when, in fact, their “partners” are merely bots delivering pre-programmed responses.
To what extent have workers been exposed to fake partners?
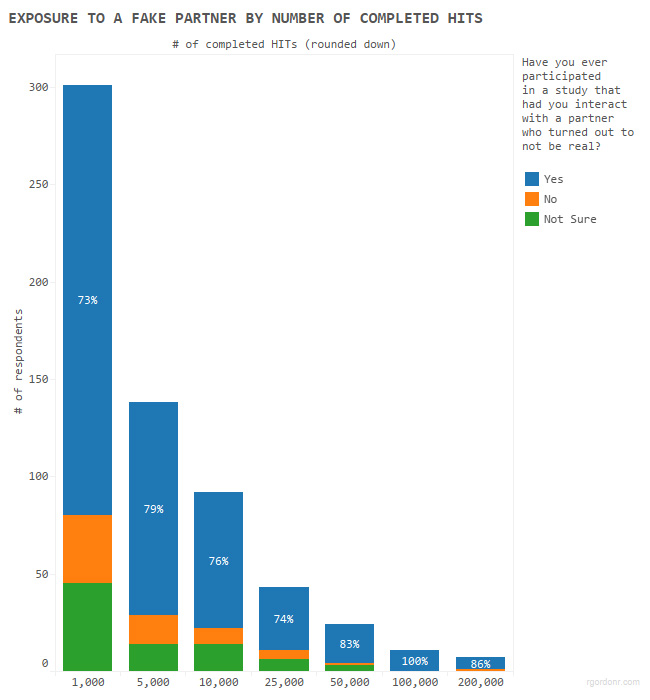
Exposure to fake partners was generally lower than exposure to exchange tasks but tended to increase more strongly as participants reported having completed more HITs. However, encounters with fake partners appear to be common across all HIT categories.
What does this mean for researchers?
The problem of non-naiveté is not due to super-turkers alone; given that most academic research is restricted to those who have completed at least 1,000 HITs, issues related to previous exposure may now be systemic — even by the time workers reach the 1,000 HIT threshold, many may already be unsuitable for certain research.
I did not measure the extent of exposure, only whether or not one had been exposed to common elements of social science research. It's difficult to tell if workers' exposure to exchange tasks at lower HIT levels is strong enough to induce mindlessness in their responses. However, any level of exposure to a fake partner seems damaging and, in my view, this exposure is sufficiently widespread to seriously compromise the effectiveness of such deception on most MTurk workers.
Although few, my data do show potentially naïve workers are still available. If common research designs are going to be used, I believe they should be accompanied by novel methods for seeking out such workers — and they will need to be novel if they're going to achieve accuracy without inducing the very suspicion they mean to detect. 4
-
The results of a HIT conducted by PBS are especially relevant to social psychology: when 100 workers were asked which questions they encountered most often, the most common were from the Rosenberg Self-Esteem Scale (reported by 38 respondents), while questions meant to prime a sense of power were the third most common (reported by 18 respondents). ↩
-
Ross, J., Zaldivar, A., Irani, L., and Tomlinson, B. 2010. “Who are the Crowdworkers?: Shifting Demographics in Amazon Mechanical Turk.” CHI EA 2010: 2863-2872. ↩
-
These data were collected between February 22nd and March 1st, 2015. The HIT was restricted to workers in the U.S. with at least a 98% acceptance rate and 1,000 completed HITs, and the HIT paid 20 cents for under 2 minutes of work. 636 responses were collected. Of these, 20 respondents (3.2%) failed an attention check. All analyses were conducted on the remaining 616 workers. ↩
-
This was essentially the same conclusion as Chandler, Mueller, and Paolacci (2013), who, as mentioned in the PBS article, reported being able to find only 5% of MTurk using research mentioning the issue of non-naiveté. ↩